In our previous exploration, we dove deep into AsyncIO by writing a task scheduler. We discovered how IO-bound operations were scheduled to the event loop concurrently while building our task scheduler project. Building on what we’ve done, we will revisit the project and scale it to run CPU-bound operations.

Join us in this journey to discover more about AsyncIO. For people who are new here, feel free to revisit our previous exploration to the topic.
- How to write an AsyncIO Telegram bot in Python
- Understanding Awaitables: Coroutines, Tasks, and Futures in Python
- AsyncIO Task Management: A Hands-On Scheduler Project
- Concurrency vs. Parallelism: Achieving Scalability with ProcessPoolExecutor
AsyncIO: A Foundation for Concurrency

It is hard to avoid talking about concurrency in discussions about asynchronous programming. However, when it gets mentioned, often times it gets mixed up with parallelism. When Golang came out, people raved about how goroutines are efficient, and that was the first time I hear people discussing concurrency after my undergrad days. Rob Pike eventually delivered a talk aiming to distinguish the two concepts and it became quite popular among my peers.
While building our project last week, I mentioned event loops functions like a timetable where we slot in awaitables for execution. They would be scheduled to run one at a time, switching to another whenever one is done, or is busy doing IO-operations. For example, when we send multiple dex tasks, it would attempt to (order is not necessarily exact, just to illustrate the idea)
- Start an HTTP request to the PokeAPI
- Wait for the response for (1)
- Start another HTTP request to the PokeAPI
- Wait for the response for (3)
- Continue the task started in (1), and compute the result
- Start another HTTP request to the PokeAPI
- Wait for the response for (6)
- Continue the task started in (3), and compute the result
- Continue the task started in (6), and compute the result
We can see the event loop improves the efficiency by keeping the CPU busy, while IO is happening in the background. This is an example of concurrency, in Pike’s word: dealing with a lot of things at once. In a way, it is like planning our time to minimize time waste on waiting in the kitchen. For example, we can proceed to cut ingredients for other dishes, while waiting for our pot of soup to boil. This allows us to concurrently prepare or cook multiple dishes at once.
So we now know we can achieve concurrency with AsyncIO for IO-bound operations. How about CPU-bound operations?
We are fortunate to live in an era where computing devices sports multicore CPU by default. Theoretically this should improve efficiency, but spreading work to multiple cores is a challenge. Continuing our cooking analogy, having an extra core or CPU is like having another kitchen and chef. Both chefs can now work together and get more dishes prepared at once. They can both choose to schedule their time wisely, to work concurrently as well.
Go’s goroutines can be scheduled to both run concurrently, or to be distributed to multiple CPU cores to run at once. In Python, we can achieve concurrency with AsyncIO. However, for parallelism, we would have to use tools like ProcessPoolExecutor in addition to AsyncIO. Let’s get started by continuing our example project last week by making fib run in parallel.
Harnessing Parallelism: ProcessPoolExecutor in Action

We usually opt to spawn a new thread, when we want to distribute work across the available cores. With threads, data can be shared among the main process and the spawn threads. However, it also means a race condition can occur when multiple threads are writing to the same variable. Hence, the global interpreter lock (GIL) was introduced, to limit the behaviour. While it protects the shared data, it makes threads inefficient as it depends on the lock.
Ensuring data is properly shared across processes and threads is therefore one of the biggest challenge in parallelism. There are ongoing efforts to deal with the limitations, or even removing GIL entirely in recent releases. But for now, most of the time we would just start new processes to distribute works to be done at once. In our case, let’s set up ProcessPoolExecutor in our repl function:
from concurrent.futures import ProcessPoolExecutor
async def repl() -> None:
with (
ProcessPoolExecutor() as executor,
suppress(asyncio.CancelledError),
):
...
Previously, in our evaluator, we would spawn a new thread whenever we work on fib, through the use of asyncio.to_thread. We also know it is just an abstraction of loop.run_in_executor. Now that we are using our own process executor, let’s revert to use run_in_executor, with our own ProcessPoolExecutor
async def evaluate(…):
match expression:
...
case Expression(command=Command.FIB):
return asyncio.get_running_loop().run_in_executor(
executor, fib, expression.args[0]
)
Now, whenever we issue a fib command, a new process is spawn instead of a thread to execute the (potentially) super slow CPU-bound operation. Starting a new process is considered more expensive, as we are pending resource allocation from the operating system. Sharing data and synchronization between processes also now require more effort, and we will discuss further about this later.
The loop.run_in_executor is essentially an abstraction of executor.submit call, where it takes function and the corresponding parameters. Therefore, in general, we would write it as
with ProcessPoolExecutor() as executor:
future = executor.submit(fib, 100)
The returned future object, has a nearly identical design compared to the asyncio counterpart, sans the asynchronous magic.
While we are at it, let’s add a new command to send multiple fib operations, where the format is fib-multi <NUM> [<NUM> …]. For instance, when we do fib-multi 100 200 300, it would schedule fib 100, fib 200 and fib 300 to run in parallel. For that, we add a new case in our evaluator
async def evaluate(...):
match expression:
...
case Expression(command=Command.FIB_MULTI):
return asyncio.gather(
*[
asyncio.get_running_loop().run_in_executor(
executor, fib2, nth
)
for nth in expression.args
]
)
When we use asyncio.gather, it takes all the awaitables passed as parameters and return a Future object. The result of the awaitables will be returned as a list when .result() is called. In our case, since we are setting the executor explicitly to a ProcessPoolExecutor, the futures are then scheduled to run in parallel.
And for that, we need to revise our job and dash to properly display the result, namely to handle cases where the result returned is a list.
def job(
task: tuple[
str,
Event | None,
asyncio.Task[str] | asyncio.Future[str] | asyncio.Future[list[str]],
],
) -> str:
try:
match task[-1]:
case asyncio.Future():
return (
"; ".join(task[-1].result())
if isinstance(task[-1].result(), list)
else task[-1].result()
) # type: ignore
case _:
return "Still waiting"
except asyncio.InvalidStateError:
return "Still waiting"
def dash(
tasks: Sequence[
tuple[
str,
Event | None,
asyncio.Task[str] | asyncio.Future[str] | asyncio.Future[list[str]],
]
],
) -> str:
result = [
"\t".join(("id", f"{'command':16s}", "done?", "result")),
"\t".join(("==", f"{'=' * 16}", "=====", "======")),
]
for num, (line, _, task) in enumerate(tasks, 1):
task_done, task_result = False, None
if task_done := task.done():
task_result = (
"; ".join(task.result())
if isinstance(task.result(), list)
else task.result()
)
result.append(
"\t".join(
(
str(num),
f"{line:16s}",
str(task_done),
task_done and str(task_result)[:16] or "",
)
)
)
return "\n".join(result)
We can now issue an actual fib-multi command, and check our system monitor to see the operating system does indeed allocate multiple processes to do the job.
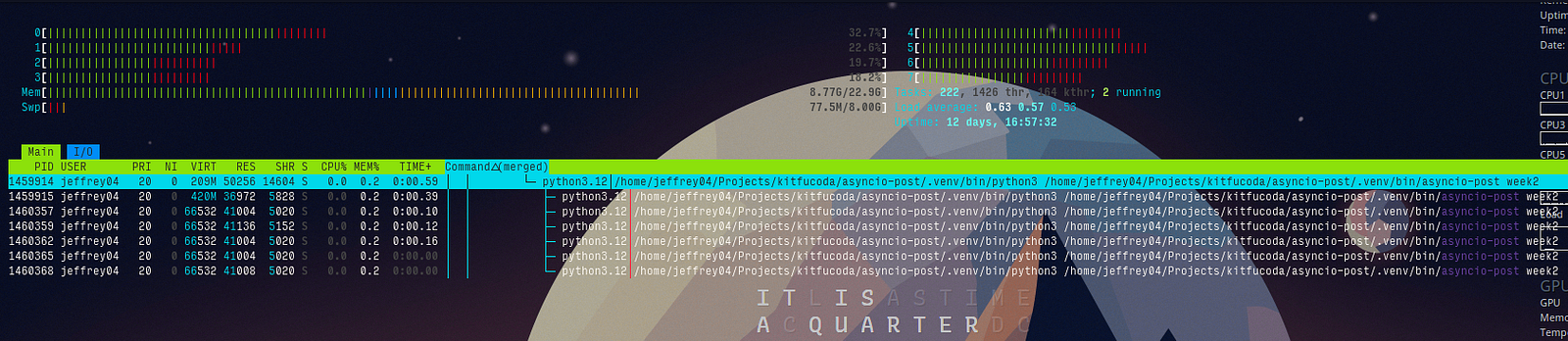
On the other hand, dex is still unaffected, and would continue to work concurrently despite the changes introduced to fib. This exercise show how it is possible to introduce parallelism into a concurrent program.
Managing Processes: Cancellation and Communication

A big drawback of starting a new process is that communication takes a lot of effort, and we lose some control over it. For instance, if we create a task in asyncio, we can cancel the task whenever needed with .cancel(). However, despite the ProcessPoolExecutor provides a .cancel() method as well, it does not always work for scheduled futures that are in progress.
One way to workaround the problem is through event objects. In our example, we will need 2 types of events, one for task cancellation, and another for application exit. Let’s get fib to subscribe to both of them.
def fib(nth, exit_event=None, cancel_event=None):
...
for i in range(1, nth + 1):
if (exit_event and exit_event.is_set()) or (
cancel_event and cancel_event.is_set()
):
return "Cancelled"
...
The key is to stop the loop, whenever either of the events is set. In our case, would be either user is exiting the program with quit, or cancelling the job with kill <NUM>. Now we move on to the evaluator to ensure both these events are sent to fib.
from multiprocessing.managers import SyncManager
async def evaluate(
…
executor: ProcessPoolExecutor,
exit_event: Event,
manager: SyncManager,
expression: Expression,
):
match expression:
...
case Expression(command=Command.FIB):
cancel_event = manager.Event()
return cancel_event, asyncio.get_running_loop().run_in_executor(
executor, fib, expression.args[0], exit_event, cancel_event
)
case Expression(command=Command.FIB_MULTI):
cancel_event = manager.Event()
return cancel_event, asyncio.gather(
*[
asyncio.get_running_loop().run_in_executor(
executor, fib, nth, exit_event, cancel_event
)
for nth in expression.args
]
)
The application exit_event is going to be applicable for all fib operations, so we are requiring it in the parameters. On the other hand, a cancel_event is only relevant for a particular job, hence it is created just for it. Then we set up the global exit_event in repl().
import multiprocessing
async def repl() -> None:
with (
ProcessPoolExecutor(max_workers=5) as executor,
suppress(asyncio.CancelledError),
):
manager = multiprocessing.Manager()
exit_event = manager.Event()
…
We create Event() object through the multiprocessing.Manager() object because it is generally more reliable, especially we are passing the object between processes.
The ShutdownHandler would require a little bit of revision so it is aware of the exit_event.
@dataclass
class ShutdownHandler:
exit_event: Event
signal: int | None = None
async def __call__(self) -> None:
logger.info("Shutting down tasks. signal:%s", self.signal or "")
self.exit_event.set()
...
Now we can prompt fib, which is our CPU-bound task to return when the application exits. The changes in the handler, also require init() function to take exit_event as parameter
def init(exit_event: Event) -> None:
loop = asyncio.get_running_loop()
for sig in (signal.SIGTERM, signal.SIGHUP, signal.SIGINT):
handler = ShutdownHandler(exit_event, sig)
loop.add_signal_handler(sig, lambda: asyncio.create_task(handler()))
loop.set_exception_handler(ExceptionHandler(ShutdownHandler(exit_event)))
Now the application exit part is done, let’s move on to task cancellation. In the evaluator, we see the CPU-bound jobs also return the cancel_event, so we need to properly store them in our list of tasks in repl()
async def repl() -> None:
...
match result := await thread_last(
line,
(tokenize, t),
(parse, g),
(
evaluate,
client,
executor,
exit_event,
manager,
tasks,
ShutdownHandler(exit_event),
),
):
case (_, asyncio.Future()):
tasks.append((line, *result))
print(f"Task {len(tasks)} is submitted")
case asyncio.Task():
tasks.append((line, None, result))
print(f"Task {len(tasks)} is submitted")
case _:
print(result)
And the corresponding kill function is now
def kill(task):
match task[-1]:
case asyncio.Task():
task[-1].cancel()
case asyncio.Future():
assert task[1]
task[1].set()
return f'Task "{task[0]}" is killed'
Note that asyncio.Task is a subclass of asyncio.Future, so the case order matters.
The Power of the Hybrid Approach

In our example, we can use ProcessPoolExecutor to introduce parallelism to our application. This allows us to scale CPU-bound operations so that they can be distributed to other cores of the CPU, allowing them to be executed simultaneously. On the other hand, IO-bound operations are still scheduled to run concurrently.
Remember the cooking analogy we mentioned earlier? Doing things concurrently is very similar to cooking. It is possible to prepare multiple dishes at a time with clever time management. While we wait for our chicken in the oven, we can go stir-fry whatever that is in the pot.
On the other hand, doing it in parallel means adding a new chef (and maybe even another kitchen). Adding a new chef, would definitely increase throughput, allowing more dishes to be done at once. On the other hand, either or both of them can still be working concurrently, increasing efficiency. In our case, it would be starting separate processes, and each manages their own event loop to take on tasks.
I hope I am doing a good enough job in this tour of AsyncIO and asynchronous programming. I certainly learned a lot throughout these few weeks, revisiting the documentation, and through building the example project. The updated project can still be accessed on GitHub, with week1 and week2 code separated, allowing comparison. Thank you again for your time, and I shall write again, next week.
This article was enhanced by the editorial assistance of a large language model, which provided valuable feedback on clarity, flow, and adherence to writing principles. While the core ideas and code remain my own, the LLM’s suggestions significantly contributed to the overall quality and readability of the piece. I am always open to collaboration on interesting projects and exploring job opportunities. Feel free to connect with me here on Medium or via my LinkedIn profile to discuss further.
Leave a Reply